
Figure 1. We analyze the effect of RL across intermediate pretraining checkpoints and across two settings: RL directly on the base model (RL Only; ), and RL after SFT (Standard Pipeline; ). We observe: (1) On-policy learning is effective starting very early during standard pretraining. models show significant improvement in both and metrics as soon as steps ( tokens) of pretraining. (2) In line with prior work, improves pass@1 performance over , but harms suggesting sharpening. (3) In contrast, consistently leads to an increase in performance suggesting that RL can actually expand the model distribution to learn new capabilities.
As of February 2026, Large Language Model (LLM) training follows a standard pipeline: pretraining supervised fine-tuning (SFT) reinforcement learning (RL) via verifiable rewards1. These stages contrast in their objectives: Pretraining and SFT employ a Next-Token Prediction (NTP) objective on a static external dataset ("off-policy"). Whereas RL employs a policy optimization objective on the model's own generations ("on-policy").
The use of two distinct training objectives raises several interesting but underexplored questions. In this work we systematically investigate this transition between off-policy and on-policy training objectives, asking:
How and when should an RL objective be used in LLM training?
Furthermore, there has been a recent growing interest in applying RL earlier in training2 3 4. As a precursor, we ask concretely: at what point during pretraining does the model's self-generated data become good enough that on-policy learning actually yields meaningful gradient signals?
To answer these questions, we perform a rigorous case study of on-policy learning with a focus on LLM reasoning capabilities. We pretrain an LLM from scratch on a high-quality, reasoning heavy corpus, and sample several intermediate pretraining checkpoints. We perform RL on the base pretraining checkpoints and study these models in comparison with (i) SFT on the base checkpoints, and (ii) the standard SFT RL pipeline. For all our experiments, we use math reasoning as a testbed since it provides a clean setting with unambiguous and verifiable rewards.
In a nutshell, we derive the following insights:
- Models start to learn from their own generations very early in training. That is, RL is effective surprisingly early in pretraining. Training with RL significantly improves performance across datasets and metrics prior to pretraining on a large number of tokens.
- RL can lead to expansion of the output distribution. Contrary to recent findings that RL only sharpens the output distribution, we find that early stage RL considerably improves pass@k performance, indicating that "expansion". We find that the sharpening vs. expansion effect with RL depends on the training pipelines.
- Effect of number of rollouts at different stages of model training. Early pretraining checkpoints might yield sparse or noisy reward. We observe that a larger number of rollouts provides diminishing returns with compute and fewer rollouts could in fact be more FLOP-efficient.
Together, our findings demonstrate the feasibility of applying RL objectives to what would typically be considered “under-trained” models suggesting that early-stage RL objectives may be effective in improving downstream performance.
Experimental Setup
Pretraining checkpoints
We pretrain a 1B-parameter decoder-only model (OLMo2 architecture5) from scratch on 50B tokens of a high-quality mixture (DOLMino, from OLMo2), saving intermediate checkpoints throughout. We then take these checkpoints and run different "post-training" pipelines from each checkpoint.
Pretraining details
- Architecture: OLMo2 1B
- Tokens: 50B total (≈ 2.5× Chinchilla-optimal6 token count for this model size)
- Optimizer: AdamW with cosine LR decay, peak LR 4e-4
- Seq length: 4096
- Batch size: 512
- Data mixture (DOLMino high-quality): Wikipedia, high-quality web, ~20% math, plus code/reasoning sources
Three training pipelines
Let Mt be the base checkpoint after t pretraining steps/tokens. We compare three distinct training pipelines:
RL only: Mt → MtRL We run RL (GRPO) directly on the base checkpoint.
SFT only: Mt → MtSFT We train on ground-truth solutions (teacher-written reasoning traces) using the NTP objective. We use the same questions as in RL, but here the model learns from expert demonstrations.
Standard pipeline: Mt → MtSFT → MtSFT→RL Taking SFT from above, we then apply RL. This is the typical modern recipe and our gold-standard baseline.
Data and evaluation
Training data: For both RL and SFT, we use OpenMathInstruct7—a dataset of math questions with multiple ground-truth solutions per question.
Benchmarks: We evaluate on GSM8K8 (grade-school math) and MATH9 (competition-level problems).
Metrics: We report pass@k for k ∈ {1, 8, 32} at temperature T = 0.6.
What is pass@k? pass@1 measures how often the model gets the right answer on its first try. pass@k (for k > 1) measures whether any of k sampled solutions is correct, telling us about the upperbound on model's reasoning capabilities.
Details on OpenMathInstruct
OpenMathInstruct consists of math questions with multiple ground-truth solutions per question. In SFT, we train on the provided solutions from the dataset. In RL, the model generates its own solutions and receives reward based on whether the final answer is correct.
The dataset contains two main categories:
- Majority: Questions inspired by the MATH dataset—challenging competition-level problems
- Minority: Questions inspired by GSM8K—grade-school level math problems
Note on evaluating base checkpoints
Pretraining checkpoints don't reliably follow instruction formatting, so we need to evaluate them differently. We care about the model's reasoning ability, not its instruction-following ability.
- Base checkpoints (Mt): Evaluated with 8-shot prompting (few-shot examples teach the format)
- All trained models (SFT/RL): Evaluated 0-shot (they learn the format during training)
Result 1: RL works surprisingly early.
Let's look at what happens when we run RL directly on early pretraining checkpoints.
Direct-RL competes with the gold standard pipeline on GSM8K.
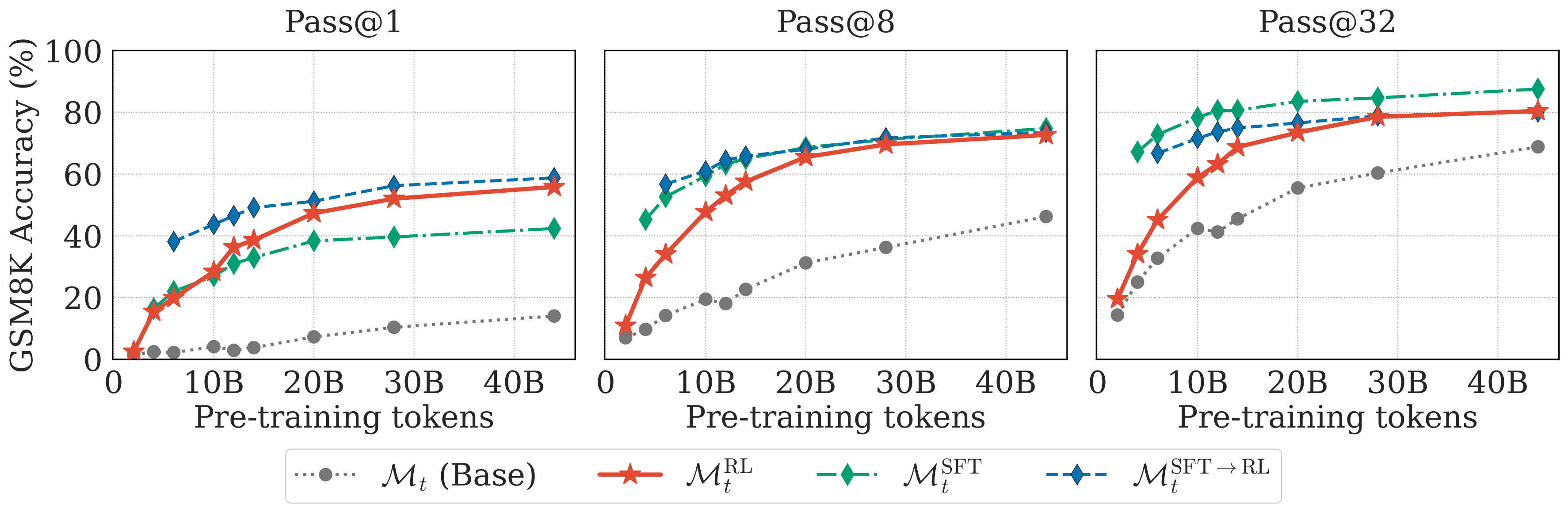
Figure 2. GSM8K results across checkpoints. RL-only improves early and can match SFT→RL after enough pretraining.
We are seeing very promising results on GSM8K. As early as 4B pretraining tokens, running RL gives us meaningful improvements. For example, pass@1 accuracy jumps from ~2% (base checkpoin, Mt) to ~18% (after RL, MtRL). What makes this especially interesting is that 4B tokens is before we've even hit the Chinchilla-optimal6 token count (i.e., 20B) for this model size. In other words, RL is helping even when the model is still pretty "under-trained" by conventional standards.
More importantly, RL-only competes with the standard pipeline. By the time we've pretrained on 10B+ tokens, the RL-only model actually outperforms the SFT-only model on pass@1, and performs on par with the full SFT→RL pipeline (MtSFT→RL, the gold-standard baseline).
We are quite surprised by this results because the RL-only model MtRL never trains on ground-truth reasoning traces. It only sees its own generated solutions, and a reward signal for whether the final answer is correct. Yet it matches or outperforms the performance of models that explicitly train on expert-written solutions. This suggests that ground-truth solution traces may not be strictly necessary to unlock certain reasoning behaviors. A pretraining model can happily bootstrap its way there from self-generated attempts.
We also see significant improvements in pass@k for k=8 and k=32, which we'll dig into more in the next section (add link here).
Limitations on MATH.
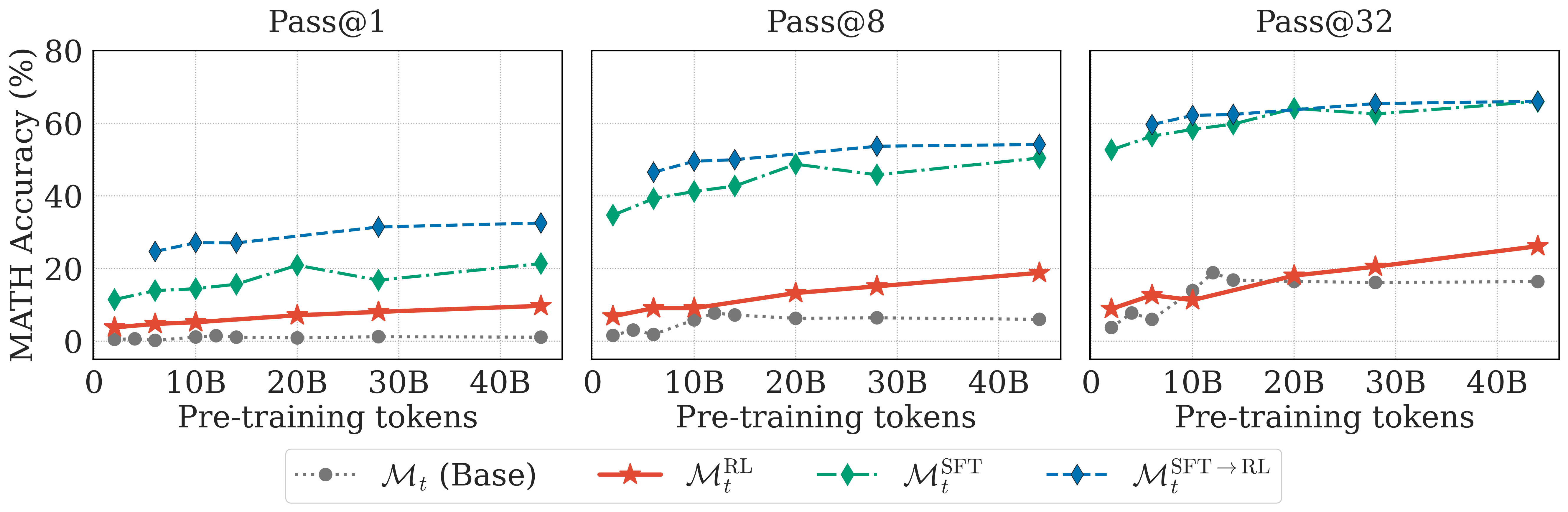
Figure 3. MATH results. RL-only improves over the base checkpoint but doesn't catch up to SFT or SFT→RL on this harder distribution.
The story on MATH is more nuanced. We still consistently see 5-10% improvements in pass@1, pass@8, and pass@32 over the base checkpoints. But on MATH, RL-only (MtRL) never quite catches up to SFT or the standard SFT→RL pipeline (MtSFT→RL). The gap persists even as we continue pretraining. MATH problems are significantly harder than GSM8K (competition-level vs. grade-school), and it seems like training purely on on-policy data from early checkpoints has its limits. The model's self-generated solutions might not be diverse or correct enough to bootstrap strong reasoning on really challenging problems.
Is this a fundamental limitation of the approach, or could we fix it with more data or a larger model? We are currently investigating this!
Result 1 takeaway: RL from early checkpoints is effective, but task difficulty matters. For easy problems, it can match the standard pipeline. For harder problems, there's still a gap.
Result 2: Can we settle the long-time RL debate, sharpening or expansion?
One of the heated debates in recent work is what RL actually does to a model's output distribution. Many works1011 12 claim that RL only sharpens the distribution without teaching any new reasoning behaviors.
We can think about RL's effect in two ways:
Sharpening: pass@1 improves, but pass@k (for large k) doesn't improve and sometimes it can even decrease. In other words, the model concentrates probability mass on a smaller set of solutions. It's getting more confident about specific paths, but not discovering new ones.
Expansion: Both pass@1 and pass@k improve together. This indicates that the model discovers more correct new successful reasoning paths it didn't have before.
Recent work has claimed that RL mostly just sharpens the distribution without giving the model genuinely new reasoning capabilities. But we found that whether RL has a sharpening or expansion effect depends on the training pipeline.
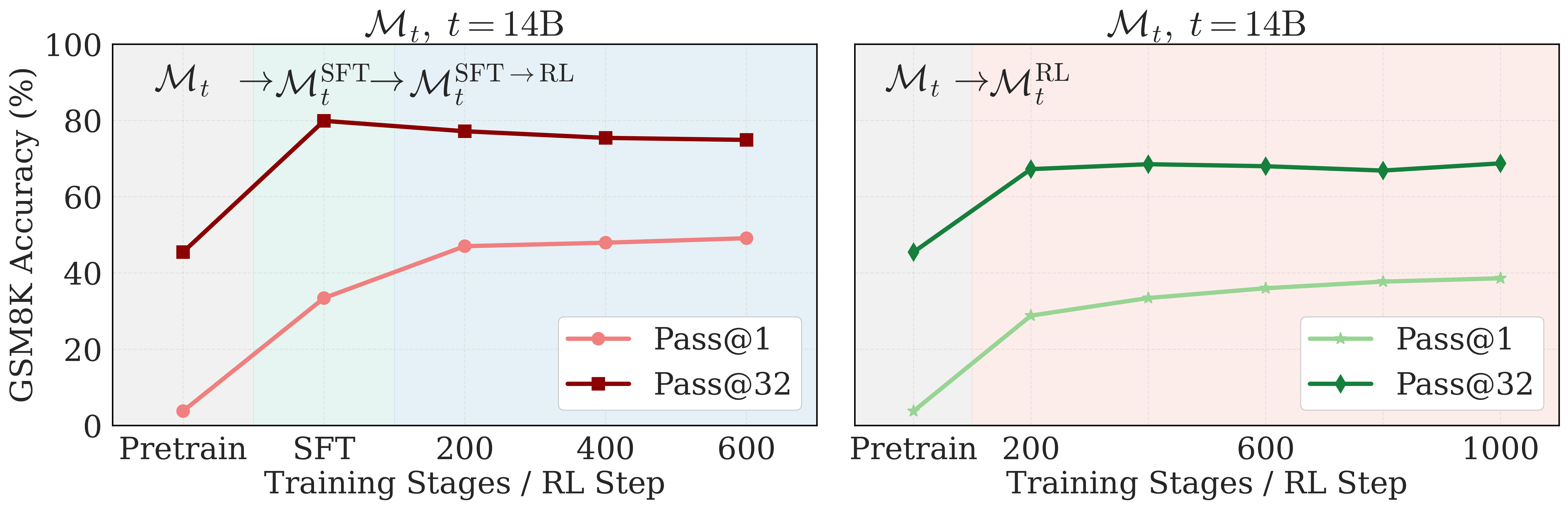
Figure 4. Training dynamics. Left: SFT→RL shows sharpening (pass@1 up, pass@32 down during RL). Right: RL-only shows expansion (both pass@1 and pass@32 up).
Standard pipeline (SFT→RL) tends to sharpen
When RL comes after SFT, we reproduce the sharpening effect that others have observed that pass@1 continues to improve during RL while pass@32 actually decreases slightly during RL (after increasing during SFT). We hypothesize that during SFT, the model has already seen ground-truth solutions for these exact questions. So when RL kicks in, it's mostly refining and concentrating around the reasoning paths it learned during SFT, rather than discovering new ones.
RL-only tends to expand
When we run RL directly on the base checkpoint (skipping SFT entirely), we instead observe the expansion effect where both pass@1 and pass@32 improve. Without prior exposure to ground-truth solutions, the model appears to explore and discover new reasoning paths through on-policy learning.
An important detour: brittleness on early checkpoints
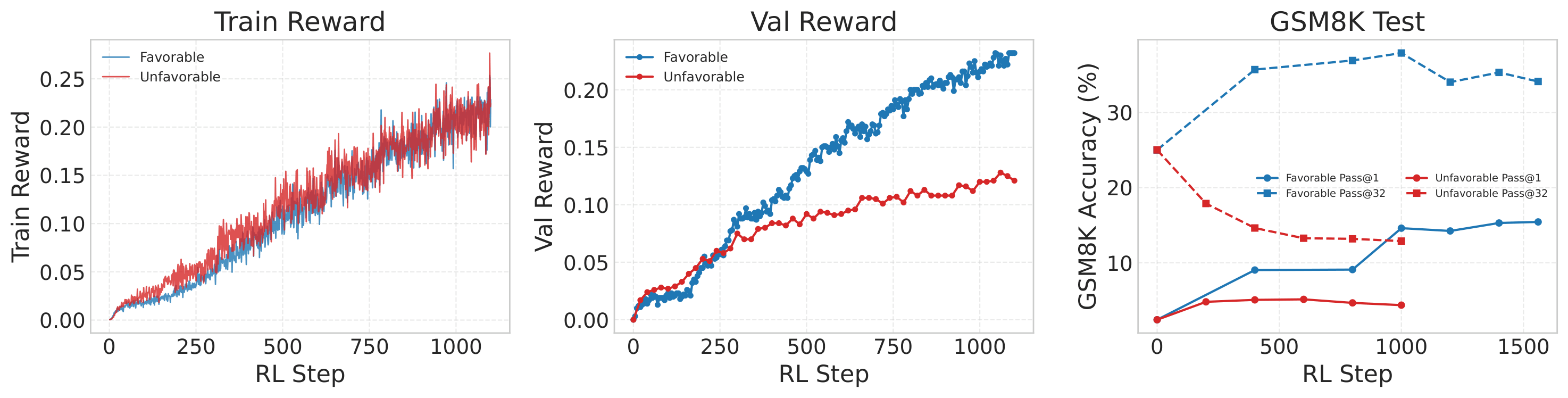
Figure A1. Seed brittleness at early checkpoints: training reward can look similar while test performance diverges sharply.
Despite these promising results, we also noticed that directly running RL on early checkpoints is unstable.
Between 4B and 10B pretraining tokens, we found that RL performance is highly sensitive to random seed. Some seeds give us significant improvements on GSM8K; others barely improve over the base checkpoint at all. But interestingly, both the good and bad seeds achieve similar training rewards. It suggests that RL on early checkpoints can sometimes lead to superficial pattern learning or memorization during RL, rather than genuine reasoning development. The model might be "gaming" the reward signal in ways that don't transfer to actual problem-solving ability. This is a real limitation we're still trying to understand.
For earlier checkpoints in our main results, we ran RL across 4 different seeds and reported the best-performing one.
Result 2 takeaway: RL's effect isn't fixed. Whether you see sharpening or expansion depends on what the model has already learned and how much room it has to explore.
Result 3: How Many Rollouts Do You Actually Need?
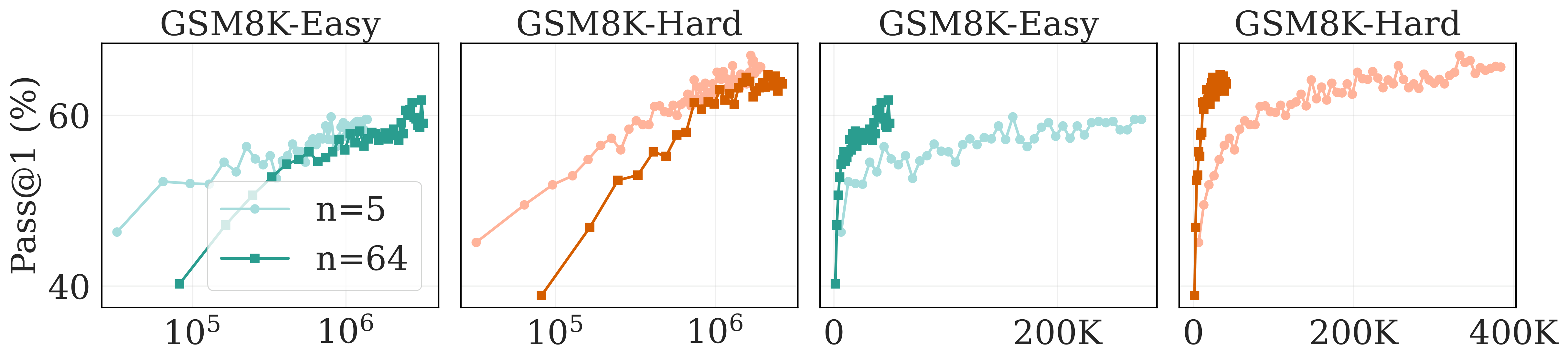
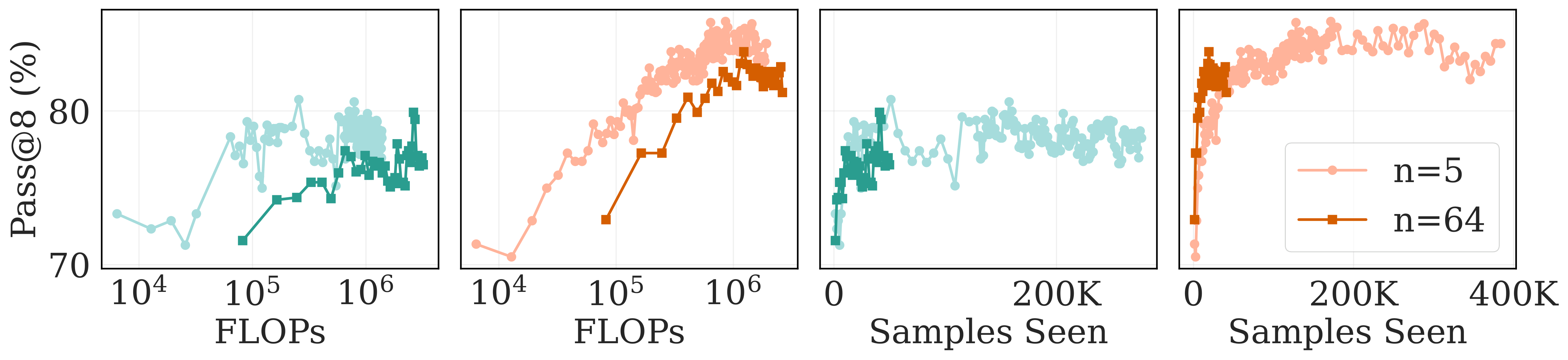
Figure 6. Rollout scaling trade-offs. pass@1 and pass@8 results for different rollout counts on GSM8K-Easy and GSM8K-Hard splits, shown as a function of both training examples and FLOPs. More rollouts improves sample efficiency, but fewer rollouts can be more FLOP-efficient—especially on the hard split.
When we ran RL on early pretraining checkpoints, we ran into a pretty practical problem: the model is pretty bad at the training questions. So we had to deal with the sparse rewards problem: most of the model's attempts are wrong, so RL doesn't get much useful learning signal from its rollouts.
We had a very natural idea: what if we just sample more rollouts per question? If the model only gets 1 out of 10 attempts right, maybe sampling 64 attempts instead of 5 will give us enough correct solutions to learn from.
However, more rollouts also means more compute per training step. So we wanted to understand when taking compute into consideration, whether increasing rollouts improve RL training.
Experimental setup
To study this properly, we simulated "easy" and "hard" training scenarios by splitting our training dataset based on how well the base model does on each question. Concurrent work13 performed analysis for number of rollouts using a similar setup. We design two subsets from OpenMathInstruct based on problem difficulty:
About OpenMathInstruct structure
OpenMathInstruct contains two main categories of questions: the majority are inspired by the MATH dataset, which consists of challenging competition-level math problems, while a minority are inspired by the GSM8K dataset, which consists of grade-school level math problems.
From the training set, we only consider GSM8k-like questions and partition them into two sets:
- GSM8K-Easy: Questions where the base model gets 16-64 correct solutions out of 64 attempts (it's doing okay)
- GSM8K-Hard: Questions where the base model gets ≤8 correct solutions out of 64 attempts (it's struggling)
We then trained with GRPO using either n=5 rollouts or n=64 rollouts per question, and tracked performance as a function of both:
- Training examples seen (sample efficiency)
- FLOPs consumed (compute efficiency)
What we found
The results reveal a clear sample efficiency vs. compute efficiency trade-off:
Sample efficiency (examples seen):
With n=64 rollouts, models converge faster in terms of training steps. You're squeezing more learning signal out of each question, so you need fewer examples to reach good performance.
Compute efficiency (FLOPs):
With n=5 rollouts, training is way more FLOP-efficient, especially early in training. You reach similar performance levels with a fraction of the compute budget.
As training continues (toward 10⁶ FLOPs), the gap narrows. Eventually n=64 catches up or even slightly surpasses n=5. But in the early stages, fewer rollouts win on compute.
Three key takeaways on rollouts
1. Final performance doesn't depend much on rollout count. Both n=5 and n=64 converge to similar pass@k peaks. You're not missing out on capability by using fewer rollouts.
2. Clear trade-off between sample and compute efficiency.
- More rollouts (n=64) gives better sample efficiency, meaning faster convergence per training step.
- Fewer rollouts (n=5) gives better compute efficiency, meaning similar performance with less compute.
3. The compute advantage is especially pronounced on hard problems. On GSM8K-Hard (where rewards are sparse), using n=5 rollouts significantly outperforms n=64 in terms of FLOP efficiency.
Result 3 takeaway: If you're training RL with sparse rewards, fewer rollouts can actually be more efficient14. You don't need massive rollout scaling to get good performance.
What's Next?
This study is very much ongoing—we see it as a controlled probe into when RL can help, not a complete recipe for replacing the standard pipeline.
Some important caveats
Task and algorithm scope:
We intentionally chose RLVR with GRPO15 and focused on math reasoning. It's a clean setup to study the problem, but by no means comprehensive. Different RL algorithms or tasks (e.g., coding, general reasoning, instruction following) might behave quite differently.
Data mixture matters:
Our base model was pretrained on a corpus with substantial math (20%) and reasoning-related content (30%). "RL readiness" likely depends heavily on what's in the pretraining mix—a model trained mostly on web text might show different dynamics.
Model scale:
All our results are from a 1B model. Larger models may show different transitions—maybe they become "RL-ready" earlier, or maybe the brittleness we observed goes away. We don't know yet.
Open directions we're excited about
Mixing RL into pretraining:
Our analysis suggests RL can be effective surprisingly early in training. This raises a natural question: what if we don't wait for pretraining to finish, but instead interleave RL with the standard next-token prediction objective during pretraining itself?
Recent work has started exploring "RL pretraining"16 2 3, but there are tons of open questions: How should you schedule the two objectives? What fraction of compute should go to each? Does the optimal data mixture change if you're doing both objectives at once?
Data mixtures and the expansion vs. sharpening effect:
We found that pretraining on lots of math makes RL effective quickly. But we also found that RL after SFT tends to sharpen rather than expand. This suggests an interesting hypothesis: the effect of RL depends heavily on what the model has already seen.
If we combine NTP and RL objectives during pretraining, maybe the optimal data mixture is different from what's currently standard. The common paradigm is to pretrain on general web data and save task-specific data for later. But if we're doing RL from the start, maybe we want more structured reasoning content earlier? Or maybe we want to ensure diversity in problem types to encourage expansion?
Appendix
We include some additional plots and ablations here.
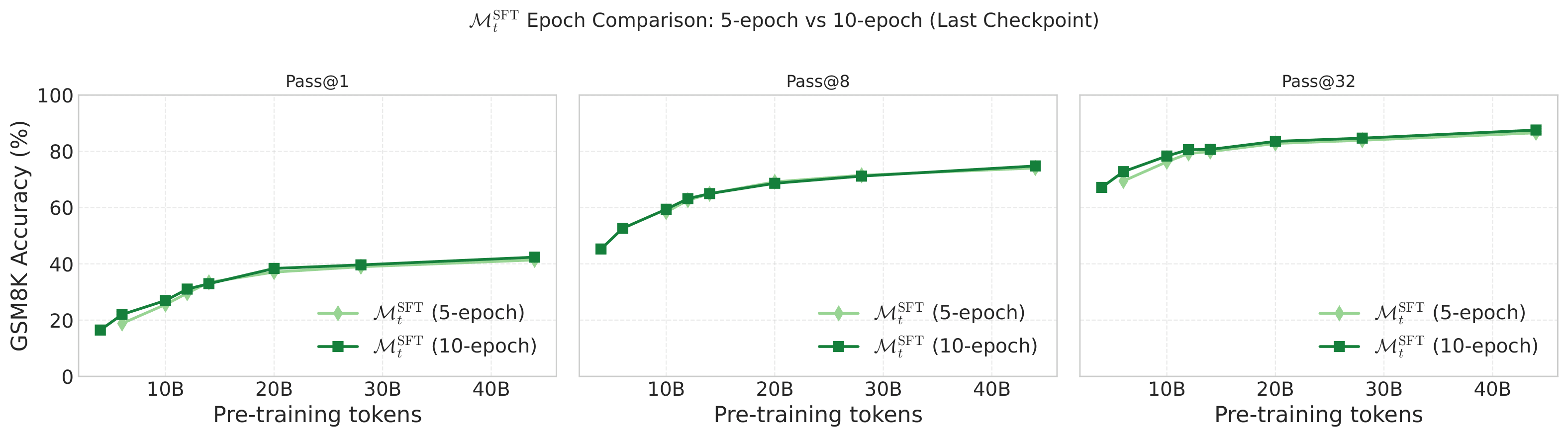
Training convergence across checkpoints
In this work, we are interested in understanding, given sufficient compute, how well each method performs. Therefore, we train all our RL and SFT runs until convergence. In the two plots below, we confirm that both our SFT and RL runs have been trained until convergence.
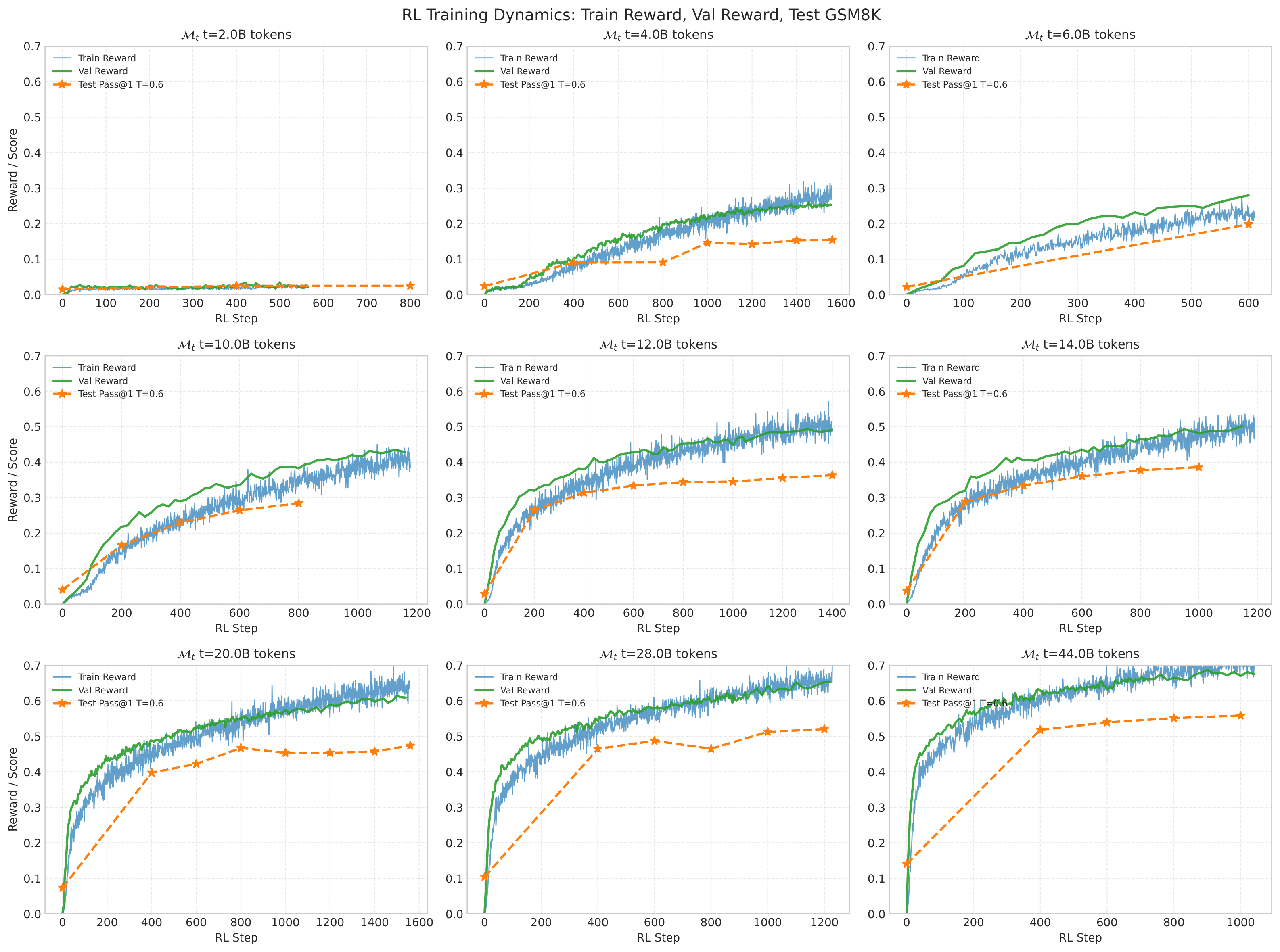
How we evaluate base checkpoints
The pretraining checkpoints do not have instruct following capabilities. Our goal is to evaluate their math capabilities, so we use 8-shot in-context examples to prompt the model to answer questions in the correct format.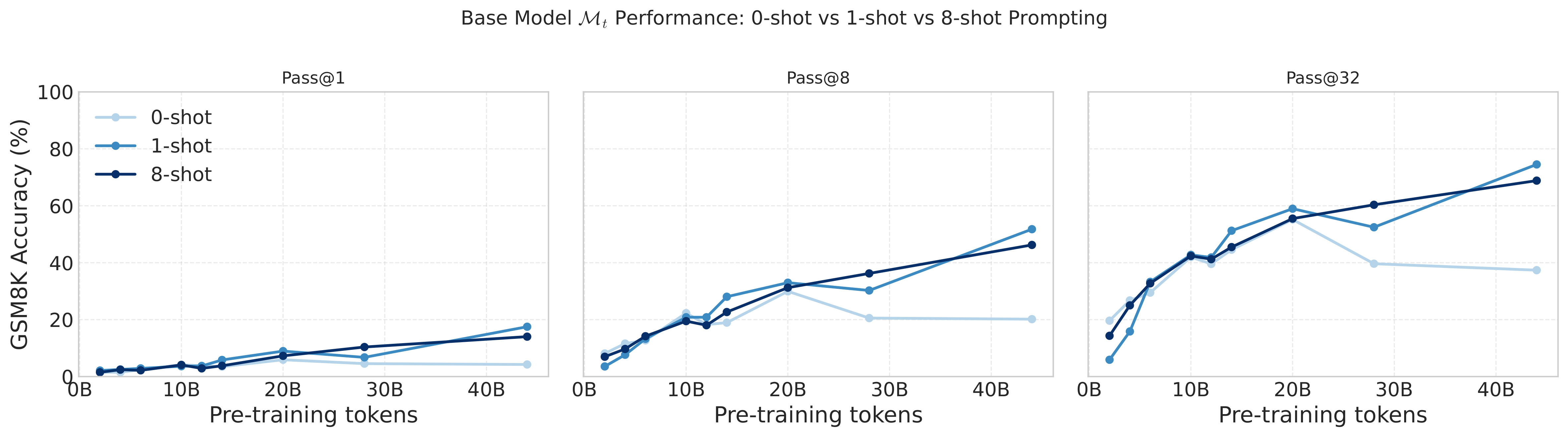
Citation
Please cite this work as:
@misc{rbcmsq2026rlexcursions,
author={Rachit Bansal* and Clara Mohri* and Tian (Sunny) Qin* and David Alvarez-Melis and Sham Kakade},
title={RL Excursions During Pretraining: How Early Is Too Early for On-Policy Learning?},
howpublished={url{https://rachitbansal.github.io/rl-excursions/}},
year={2026}
}
Feedback?
These are open questions we're still thinking about; we'd love to hear your thoughts!
This is a living document. If you have questions, ideas, or want to discuss any of these findings, feel free to reach out!